 Bij websites waar veel items aangeboden worden, bestaat normaal gesproken de mogelijkheid de items te sorteren, te filteren en door de items te bladeren. Meoestal betreft het webshops maar het kunnen ook blogs zijn. Technisch gezien zijn er vele mogelijkheden om deze functionaliteiten te implementeren. In mijn SEO-praktijk zie ik de meest wonderlijke oplossingen langskomen. Soms zijn die oplossingen, bezien vanuit SEO, simpelweg fout, vaak ook zijn ze niet-optimaal. In dit artikel zal ik op een rijtje zetten waar u bij het implementeren van deze funtionaliteiten rekening mee moet houden om een voor SEO optimale situatie te creëren.
Bij websites waar veel items aangeboden worden, bestaat normaal gesproken de mogelijkheid de items te sorteren, te filteren en door de items te bladeren. Meoestal betreft het webshops maar het kunnen ook blogs zijn. Technisch gezien zijn er vele mogelijkheden om deze functionaliteiten te implementeren. In mijn SEO-praktijk zie ik de meest wonderlijke oplossingen langskomen. Soms zijn die oplossingen, bezien vanuit SEO, simpelweg fout, vaak ook zijn ze niet-optimaal. In dit artikel zal ik op een rijtje zetten waar u bij het implementeren van deze funtionaliteiten rekening mee moet houden om een voor SEO optimale situatie te creëren.
Sleutelfactoren bij de bepaling van SEO-optimale oplossingen voor genoemde functionaliteiten zijn twee zaken, namelijk:
- Dubbele content
- Crawl budget
Dubbele content
Wat dubbele content betreft, is het de vraag in hoeverre bijvoorbeeld een op prijs gesorteerde pagina wezenlijk anders is dan een ongesorteerde of een op alfabet gesorteerde pagina. Als er geen wezenlijke verschillen zijn kunnen we de gesorteerde pagina als dubbele content pagina beschouwen om vervolgens de juiste seo-technieken toe te passen. Die technieken zijn gericht op het voorkomen van de situatie dat de PageRank (PR) in de site naar de onbelangrijke (lees: dubbele content) pagina’s stroomt en dus ten koste gaat van de belangrijke (lees: unieke). De PR in de site wordt bepaald door de verwijzingen (hyperlinks) naar de site en kunnen we beschouwen als een bodem onder het scorend vermogen van de (pagina’s binnen de) site. De aanwezige PR willen we dus optimaal benutten.
Crawlbudget
Wat crawlbudget betreft (bij mijn weten als begrip voor het eerst gebruikt in een interview van Eric Enge met Google woordvoerder Matt Cutts in 2010), moet u weten dat googlebot slechts een beperkte -laten we zeggen- ‘energie’ heeft om de pagina’s van uw site te crawlen (en vervolgens te indexeren en ranken). De energie die het heeft, wordt bepaald door -wederom- de PR in uw site. Als we SEO-optimale oplossingen gaan definiëren voor het sorteren, filteren en bladeren moeten die oplossingen zo goed mogelijk omspringen met het gelimiteerde budget. In dat geval zal Google namelijk meer energie overhouden voor het crawlen van de pagina’s die er meer toe doen. Dit lijkt misschien een kleinigheidje, maar is het meestal niet: indien de site veel mogelijkheden kent voor sorteren, filteren en bladeren, dan resulteert dit al snel (ook doordat er verschillende combinaties mogelijk zijn) in een enorme hoeveelheid extra URL’s.
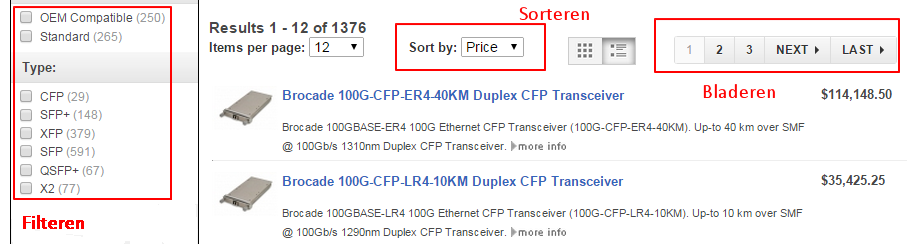
Voordat we nu overgaan tot het individueel bespreken van de juiste manier van filteren, sorteren en bladeren volgt hier een afbeelding (van een webshop die ik recent onder handen heb gehad) waar we de drie functionaliteiten duidelijk in beeld zien:
Sorteren
Uit verschillende publicaties van Google (zie ook ‘Bronnen’ onderaan dit artikel) blijkt dat een gesorteerde pagina voor hen niet wezenlijk anders is dan de ongesorteerde pagina. Als we in een kledingwebshop alle jurkjes (eindelijk lente…) op lengte sorteren, of op alfabet of op kleur, dan verandert de content dus feitelijk niet. Ok, de volgorde is anders, maar de inhoud niet.
Feitelijk heeft het dus geen zin de gesorteerde varianten van de oorspronkelijk pagina zichtbaar te maken voor Google. Alle sorteringen mogen dus onder één en dezelfde URL plaatsvinden. Dit kan bijvoorbeeld gerealiseerd worden door de toepassing van AJAX. Let daarbij wel op dat Google in ieder geval wel de oorspronkelijke sortering moet zien: als die ook via AJAX wordt gegenereerd is er een goede kans dat Google die niet ziet. Dit kan gecontroleerd worden door in het Google-zoekvenster cache:<url> in te typen om daarna te klikken op de link ’tekstversie’. Het mooie van de oplossing waarbij zowel de oorspronkelijke als gesorteerde varianten van de pagina onder één URL plaatsvinden, is dat we ons gelimiteerde crawlbudget ideaal inzetten: er hoeft immers maar één pagina te worden gecrawld.
Bij de controle of de sorteringen binnen onze site al dan niet onder één en dezelfde URL plaatsvinden moet u weten dat Google alles achter een eventuele hashtag in de URL, negeert. Een URL als /jurkjes#kleur is voor Google dus feitelijk dezelfde URL als /jurkjes. Indien de sorteringen getoond worden onder /jurkjes#kleur, /jurkjes#lengte, etc., ziet Google dus maar één pagina, namelijk /jurkjes. Indien er de voor SEO zo belangrijke verwijzingen gaan ontstaan naar bijvoorbeeld /jurkjes#kleur of /jurkjes#lengte, dan gaan die dus automatisch tellen voor /jurkjes. En dat is precies wat we willen.
In de meeste shops en blogs leiden sorteringen wél tot werkelijk afzonderlijke URL’s. De fout die hier vervolgens nog wel eens wordt gemaakt is dat de gesorteerde varianten van de pagina via de rel=nofollow worden aangeroepen vanuit de (dus op zich juiste) gedachte dat die pagina’s toch niet interessant zijn voor Google. Toepassing van de rel=nofollow maakt echter dat de kracht (ook wel link juice of link equity genoemd) die normaal gesproken via de link naar de betreffende pagina zou zijn gegaan uit de site verdwijnt. En vanuit SEO bezien is dat daarmee een foute oplossing.
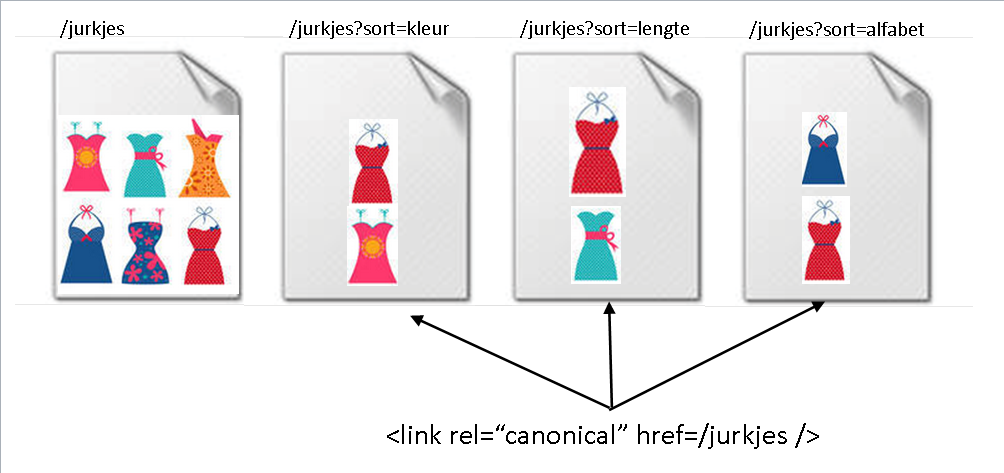
De optimale oplossing bij sorteringen op werkelijk afzonderlijke URL’s is dat in de head van iedere sorterings-URL een rel=canonical wordt gespecificeerd. Via de rel=canonical geven we aan Google aan welke variant (van alle sorteringen) door Google moet worden gezien als canonieke- of hoofdpagina. Het mooie van de rel=canonical is dat de scoringskracht van alle niet-canonieke pagina’s (als gevolg van de verwijzingen er heen) wordt opgeteld bij de canonieke pagina, waardoor die laatste alle scoringskracht gaat krijgen en de niet-canonieke pagina’s uit de index verdwijnen. Googlebot hoeft zijn cralwbudget ook in deze oplossing dus niet meer te besteden aan alle sorteringsvarianten van de pagina. Vanuit het oogpunt van SEO is deze oplossing daarom net zo goed als de oplossing waarbij alles onder één URL zou hebben plaatsgevonden. Hier ziet u de canonieke oplossing nog eens grafisch weergegeven aan de hand van het jurkjes-voorbeeld.
Filteren
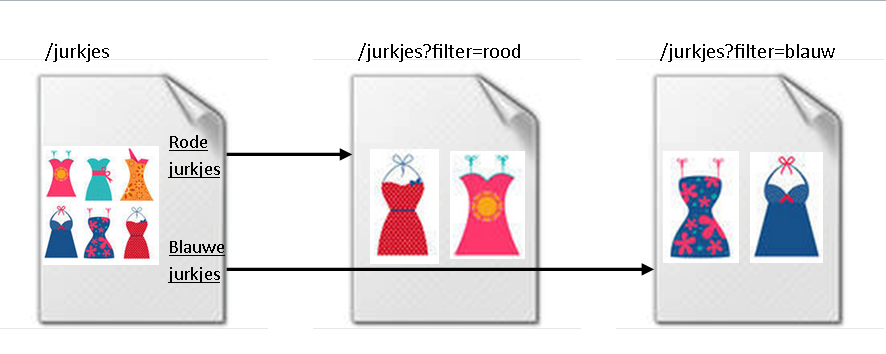
Gefilterde pagina’s zijn -in de ogen van Google- wél wezenlijk andere pagina’s dan ongefilterde pagina’s of pagina’s met een ander filter. Een pagina met rode jurkjes, bijvoorbeeld, is dus een andere pagina (d.w.z. bevat formeel andere content) dan een pagina met alle jurkjes of met gele jurkjes. Bij het filteren moeten we de output dus in principe níet onder dezelfde URL plaatsen. Dit sluit ook aan bij ons eigen SEO-gevoel: als er geen afzonderlijke URL voor ‘rode jurkjes’ is, lopen we de mogelijkheid mis om daar een mooie, geoptimaliseerde pagina voor te realiseren.
Omdat gefilterde pagina’s wezenlijk verschillende pagina’s zijn mogen (en willen) we hier dus ook niet gaan werken met de rel=canonical. Ga filters ook niet blokkeren via de rel=nofollow, via de meta noindex of uitsluiten via de robots.txt: we willen juist dat Google de gefilterde pagina ziet en zo goed mogelijk begrijpt. De rode jurkjes pagina gaan we daartoe perfect optimaliseren op ‘rode jurkjes’ door die zoekterm te verwerken in de Title, H1, URL, content en ankerteksten (dwz de zichtbare tekst in de link) van de verwijzingen naar die pagina.
Zorg er daarbij wel voor dat de filters voor Google zichtbaar zijn als gewone linkjes (met de juiste ankerteksten). Indien het filteren bijvoorbeeld via javascript verloopt, of via html-forms, dan is er een goede kans dat Google het filter niet als link herkent waardoor de filter-pagina niet wordt ontdekt en (als die wel al via een omweg, bijvoorbeeld via de sitemap, wordt ontdekt) niet de maximale kracht mee krijgt.
Indien de site echter heel veel filterpagina’s kent die voor optimalisatie niet interessant zijn, en het crawlbudget (lees: PR) van de site relatief laag is, dan is het echter weer niet slim om al die filterpagina’s te laten indexeren. Dat gaat immers ten koste van de kracht naar weer andere, mogelijk belangrijkere, pagina’s. Een filterpagina als /jurkjes?filter=blauw-met-lichtblauwe-stippen-en-roze-bloemetjes zal niet veel toevoegen, omdat men daar toch niet naar zoekt. In dat geval moeten we óf -net als bij het sorteren- bepaalde filterpagina’s via de hashtag-constructie onder één gemeenschappelijke URL gaan brengen óf -en dat is normaal gesproken eenvoudiger- Google’s Search Console in het verhaal gaan betrekken. Meer over de Search Console later in dit artikel.
Bladeren
Indien we niet alle items op één pagina willen of kunnen tonen, dan nemen we bladerbuttons op. Dat zien we natuurlijk veel bij webshops, maar ook onderhavige blog heeft bladerbuttons om zodoende de verwijzingen naar alle blogartikelen over meerdere pagina’s te kunnen verdelen.
Via de hyperlinks van de ene bladerpagina naar de volgende kan Google de uiteindelijke items (de concrete producten, blogartikelen, etc.) vinden. Het is dus belangrijk dat de bladerpagina’s goed gelinkt worden en zichtbaar zijn voor Google. Controleer ook dit via het “cache:<url>”-commando. Indien we alle bladerpagina’s onder één en dezelfde URL zouden tonen is de kans groot dat Google vele items in onze shop of blog niet kan vinden: alleen de eerste pagina wordt dan normaal gesproken gecacht. Om alleen al die reden moeten we er voor zorgen dat iedere bladerpagina een eigen URL krijgt.
Hier komt nog bij dat blader-pagina’s, ook voor Google, verschillende content bevatten. We kunnen hier dus niet werken met rel=canonical’s van de bladerpagina’s naar bijvoorbeeld de eerste pagina in de lijst. Ga ook niet de verschillende bladerpagina’s blokkeren via de rel=nofollow, via de meta noindex of uitsluiten via de robots.txt. Het punt is namelijk dat de kracht die bij de bladerpagina’s aankomt (via de interne en eventuele inkomende verwijzingen) benut moet gaan worden voor het beter scoren met de onderliggende items (concrete producten, blogberichten), hetgeen niet plaatsvindt bij blokkade of uitsluiting van de pagina’s: dan vervliegt de kracht.
Google zegt bladerpagina’s normaal gesproken goed te kunnen detecteren. In principe hoeven we op dit punt dus niets te doen. Als we er desalniettemin niet helemaal zeker van zijn dat Google de bladerstructuur inderdaad goed snapt, dan kunnen we Google op een eenvoudige manier helpen.
Google heeft namelijk twee attributen in het leven geroepen om de kracht in de bladerpagina’s te bundelen in de eerste pagina: de rel=prev en rel=next.
===
Let op: Google heeft bij monde van John Mueller in maart 2019 aangegeven dat de rel=prev/next niet meer door hen wordt ondersteund. Google is inmiddels zelf goed in staat om de eerste pagina te vinden en daarin de kracht te bundelen.
===
Via deze attributen kunnen we aan Google uitleggen hoe de keten van bladerpagina’s precies in elkaar steekt. Anders gezegd: we geven betekenis (semantiek) aan de bladerbuttons op de pagina’s. In de headsectie van de pagina’s nemen we we de volgende regels code op:

We geven dus precies aan welke pagina ervoor komt en welke erna. De eerste pagina in de lijst heeft alleen een ‘erna’ en de laatste alleen een ‘ervoor’. Google zal de scoringskracht van alle (in dit voorbeeld negen) pagina’s bundelen in de eerste (/jurkjes). Althans, ze behouden zich het recht voor om hiervan af te wijken: de rel=next/prev fungeren als -wat ze noemen- ‘strong hints’. Als ze de hint overnemen zal die eerste pagina beter gaan scoren, terwijl de overige acht uit de index gaan wegvallen. Op deze manier komt de kracht van een verwijzing naar bijvoorbeeld pagina /jurkjes?p=6 terecht bij /jurkjes. En dat is precies wat we normaal gesproken willen. Alleen in de situatie waarbij u juist wilt dat specifieke bladerpagina’s ook worden geïndexeerd, is het niet raadzaam deze rel=next/prev constructie toe te passen. Want alleen de eerste pagina zal nog (versterkt, dat dus wel!) in de zoekresultaten gaan verschijnen.
Een tweede oplossing die Google biedt voor bladerpagina’s is dat we niet de eerste pagina gaan laten scoren, maar een extra overzichtspagina met álle producten. In dat geval, zegt Google, is het geheel van items op de bladerpagina’s wezenlijk identiek aan de items op de extra overzichtspagina en mag de rel=canonical dus worden toegepast. Maar hoe dan? Welnu, door op alle bladerpagina’s de rel=canonical op te nemen naar de overzichtspagina:
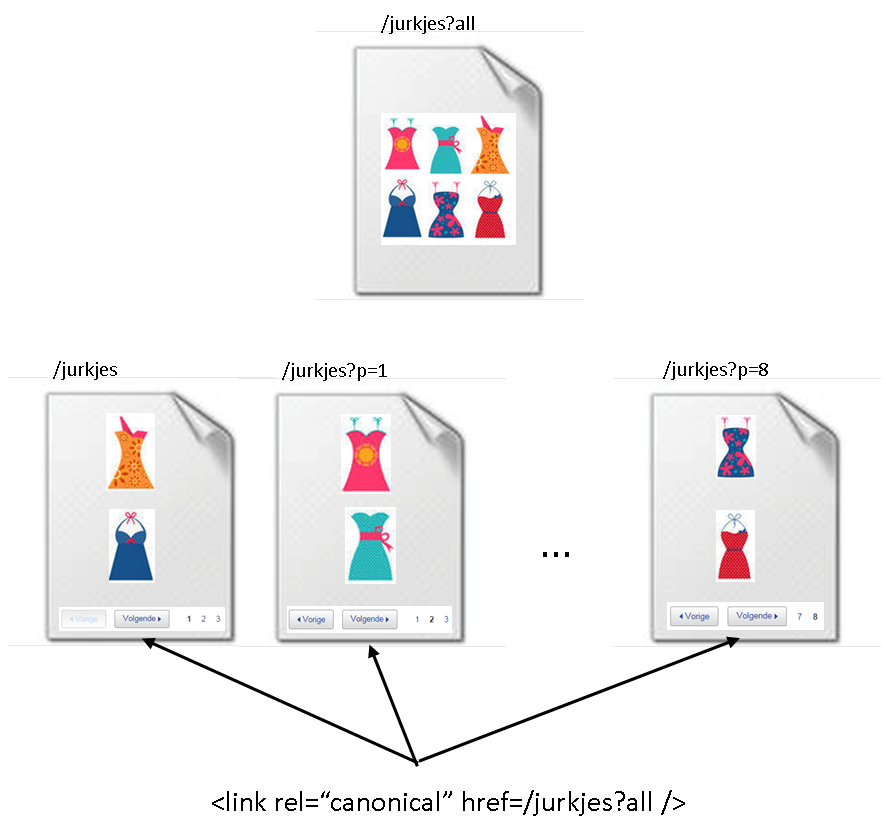
Alle scoringskracht van de negen bladerpagina’s gaat nu over op /jurkjes?all, waarbij ze zelf uit de index gaan verdwijnen.
De toepassing van deze bladerconstructies maakt dat ons crawlbudget veel beter wordt besteed: uiteindelijk hoeft Google nu nog maar één pagina te crawlen namelijk of alleen de 1e pagina in de lijst (bij toepassing van de rel=next/prev) of alleen de overzichtspagina (bij toepassing van de rel=canonical).
Eduard Blacquière heeft aug. 2012 overigens al eens onderzoek uitgevoerd naar het effect van de rel=next/prev en kwam tot de conclusie dat er een stevige ’traffic boost’ door oa. betere rankings kan plaatsvinden.
Google Search Console
Er is een tweede manier om aan Google te verduidelijken (d.w.z. een ‘strong hint’ te geven) dat het sortering-, filter- of blader-URL’s betreft, namelijk via Google Search Console (de optie Crawlen – URL parameters). Die specifieke functionaliteit is echter alleen gericht op parameters in de URL’s. Parameters zijn feitelijk variabelen in de URL die we rechts naast een vraagteken tegenkomen, ‘Get-variabelen’ noemen we die. In de URL /jurkjes?sort=kleur hebben we inderdaad een parameter, namelijk ‘sort’. In plaats van, of eventueel parallel aan, de oplossing zoals hiervoor beschreven om via de rel=”canonical” de verschillende sorteringen naar één canonieke pagina te laten verwijzen, kunnen we dit ook specificeren via Search Console. We geven daar aan dat de parameter ‘sort’ Sorteert. Op dezelfde manier kunnen we aangeven dat de parameter ‘p’ (zie voorbeelden hierboven onder ‘Bladeren’) Pagineert en ‘filter’ (zie voorbeeld hierboven onder ‘Filteren’) Specificeert.
Indien de sorteer-, filter of bladerpagina’s niet via GET-variabelen verloopt, kunnen we Google dus niet helpen via de Search Console. Als de URL van de filterpagina bijvoorbeeld /jurkjes/sort/kleur/ is, dan is er geen GET-variabele aanwezig en rest ons niet anders dan te werken met de rel=canonical.
Slotwoord
Bij het analyseren van websites zien we vaak zeer wonderlijke implementaties van filters, sorteringen en bladeren. Elke implementatie vraagt om eigen, specifieke oplossingen en aanpassingen. Ik hoop (en verwacht) dat u nu met meer kennis naar (uw eigen) sites kunt kijken en kunt beoordelen in hoeverre die SEO-technisch optimaal in elkaar zitten en welke verbeteringen ze behoeven. Inzicht in de twee begrippen ‘Dubbele content’ en ‘Crawlbudget’ is daarbij dus cruciaal. Waarom ook al weer? Om een derde begrip, namelijk de in de website aanwezige ‘PageRank’, optimaal in te kunnen zetten voor het scoren met de kortste jurkjes belangrijkste pagina’s in de site. Easy 😉
Bronnen
Google Webmastercentral Blog – specify your canonical Google webmaster tools Help – Content guidelines Stone Temple Consulting – Matt Cutts Interviewed by Eric Enge Google Webmastercentral Blog – Video about pagination with rel=“next” and rel=“prev” Edwords – Case: Hoe Googlebot Omgaat Met Rel=”Prev” & Rel=”Next” Searchengine Watch – Ecommerce SEO, filtering and segmentation
Alain,
Complimenten! Heldere uitleg met goede voorbeelden. Hopelijk lezen veel webbouwers dit artikel en houden ze hier voortaan rekening mee. En anders kunnen we mooi een linkje naar deze pagina sturen
🙂
Eindelijk iemand die weet waarover hij praat. Zeer duidelijk in ‘Jip en Janneke taal’ verwoord.
Wederom bedankt, lees vaak jullie website door om mijn kennis op pijl te houden, goede artikelen 🙂
Keep on the good work!
Ik was op zoek naar de juiste codes: rel=…. Heb hier gevonden. Bedankt!
Klasse uitgelegd Alain. Ik zeg altijd tegen mijn klanten: van elke pagina met dezelfde content, mag er slechts één operationele URL zijn. Filters worden hier nogal vaak bij vergeten helaas.
Helder omschreven met duidelijke voorbeelden, waarvoor mijn complimenten Alain. Het is soms moeilijk voor klanten om – een stortvloed aan – informatie allemaal mee te krijgen. Daar bieden blogs als deze mede een uitkomst!
Wat een goed idee om alle gesorteerde pagina’s onder één URL te laten vallen en bedankt om duidelijk voor te stellen wat het verschil is voor Google tussen gesorteerde en gefilterde resultaten!